
Background
So you’ve learned all about BeautifulSoup. What’s next? Python is a great language for automating web operations. In a previous article we went through how to use BeautifulSoup and requests to scrape stock-related articles from Nasdaq’s website. This post talks about a couple of alternatives to using BeautifulSoup directly.
One way of scraping and crawling the web is to use Python’s RoboBrowser package, which is built on top of requests and BeautifulSoup. Because it’s built using each of these packages, writing code to scrape the web is a bit simplified as we’ll see below. RoboBrowser works similarly to the older Python 2.x package mechanize in that it allows you to simulate a web browser.
A second option is using requests_html, which was also discussed here, and which we’ll also talk more about below.
Let’s get started with RoboBrowser!
To install RoboBrowser, you can use pip:
pip install robobrowser
Once installed, we’ll load the package like so:
from robobrowser import RoboBrowser
Next, let’s create a RoboBrowser object, which will serve as an invisible browser. We can use this browser-like object to navigate to websites, like Google.
# create a RoboBrowser object
browser = RoboBrowser(history = True)
# navigate to Google
browser.open("http://www.google.com")
We can verify we’re currently at Google’s homepage by checking the url attribute of browser:
browser.url # "https://www.google.com/"
Submit a form with RoboBrowser
Now that we’ve navigated to Google’s search homepage, let’s simulate searching for a company’s name. We can find the search query form on Google by using the get_form method.
search = browser.get_form()
For webpages with multiple forms, you can use the get_forms method (note: forms instead of form). In that case a list of all the forms on the webpage will be returned. Calling get_form will return only the first form found on the webpage. We can see the difference in the snapshots below.


To submit our query for a regular Google search, we write the following code:
search["q"] = "aapl" browser.submit_form(search, submit = search.submit_fields["btnG"])
The first line above specifies we want the value of the form’s q attribute to be “aapl”. This is equivalent to typing “aapl” into Google’s search box.
The search.submit_fields[“btnG”] tells our browser object that we want to search using the standard Google search method. If want to use search using the “I’m feeling lucky” option, we just tweak our code like this:
browser.submit_form(search, submit = search.submit_fields["btnI"])
BeautifulSoup vs. RoboBrowser
We can scrape all of the links off the webpage using the get_links method.
links = browser.get_links()
urls = [link.get("href") for link in links]
In comparison, BeautifulSoup code for what we did above would look like this:
import requests
from bs4 import BeautifulSoup
resp = requests.get("http://www.google.com/search?q=aapl")
soup = BeautifulSoup(resp.content)
# get links
links = soup.find_all("a")
# get urls
urls = [link.get("href") for link in links]
The main advantage of RoboBrowser versus BeautifulSoup / requests is that it behaviors similarly to an actual browser, so it can fill in forms, like the search query above, or click on links like below, using the follow_link method, all in one package.
browser.follow_link(links[0])
RoboBrowser also allows you to effectively use functionality from BeautifulSoup. Take for example the find_all method:
# get all links - "a" tags
browser.find_all("a")
# find all div tags
browser.find_all("div")
This works just like in BeautifulSoup, where you pass whatever tag you want to search for on the webpage. You also parse out information from various tags the same way.
# get text from link links[0].text
RoboBrowser, like a typical web browser, also allows you to “go back” or “forward” using the back or forward methods, respectively.
# go back to previous page browser.back() # check URL print(browser.url) # go forward browser.forward() # check URL again print(browser.url)
In summary, RoboBrowser gives you the same HTML parsing abilities as BeautifulSoup, but also allows you to fill out forms, and perform browser-like functions. One drawback of RoboBrowser is that it is not able to scrape JavaScript-rendered pages, unlike requests_html.
You can check out the RoboBrowser documentation here.
Working with requests_html
requests_html can be installed via pip. This package requires Python 3.6+. requests_html, in effect, provides requests functionality, while also adding on web parsing abilities.
pip install requests-html
Te get started with requests_html, we establish a session object that we will use to connect to webpages and scrape information.
from requests_html import HTMLSession
# establish a session
session = HTMLSession()
# connect to needed webpage
resp = session.get("http://www.google.com/search?q=aapl")
Getting the URLs on the webpage is pretty intuitive:
resp.html.links

Note: resp.html.links doesn’t return link objects i.e. it does not return objects representing anchor, or “a” tags. Rather, it just returns the URLs directly from a webpage.
Specifically, resp.html.links, similar to how we scraped links with BeautifulSoup or RoboBrowser, returns the relative links on the webpage. To get the absolute links in any of these cases, you could use another package, like this:
from urllib.urlparse import urljoin
# taking urls list from above
full_urls = [urljoin("http://www.google.com", url) for url in urls]
requests_html, on the other hand, can do this internally with just a simple tweak to our line of code above:
resp.html.absolute_links
Here, we use absolute_links, rather links.
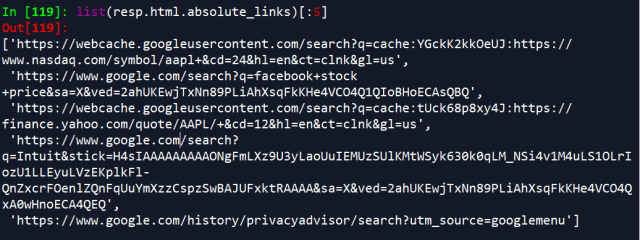
If you want to get the link objects, or scrape any other tags, you can use the find method.
# get all link objects ("a" tags)
resp.html.find("a")
# scrape all div tags
resp.html.find("div")
Then we can scrape the text of all the links like this:
links = resp.html.find("a")
# get text of each link
[link.text for link in links]
If you want to filter your results to only links containing the word “search” in the URL, you can do that also in one line like this:
resp.html.find("a", containing = "search")
Or, you replace “search” with whatever other word you’re looking for.
You can get the attributes of a single tag using the attrs method.
links[0].attrs
requests_html also allows you to search for text on a page. In the example below, Python returns the word “and” because that word appears between “trade” and “investing” in the search results, the phrase input into the search method.
resp.html.search("trade {} investing") # and
Pagination
requests_html also, to an extent, is able to identify sequential webpages (like the snapshot below).
resp = session.get("https://www.nasdaq.com/symbol/nflx/news-headlines")
Once we connect to this webpage (https://www.nasdaq.com/symbol/nflx/news-headlines), we get the next page URL in the sequence like this:
resp.html.next() # "https://www.nasdaq.com/symbol/nflx/news-headlines?page=2"
To request the next page, we can just do this:
resp2 = session.get(resp.html.next())
To request the first ten pages, and store each request object in a list, we could do this:
resp = session.get("https://www.nasdaq.com/symbol/nflx/news-headlines")
resp_objects = [resp]
page_num = 1
while page_num <= 9:
resp = session.get(resp.html.next())
resp_objects.append(resp)
print(resp.url)
page_num += 1

Then we could get the absolute URLs for each of the ten pages:
urls = [resp.html.absolute_links for resp in resp_objects]
all_urls = []
for links_set in urls:
all_urls.extend(links_set)
Check out the documentation for
To learn about scraping JavaScript webpages with requests_html, click here.
That’s it for this post! If you like this blog, please subscribe via the right side of the page.