
Background
If you’ve done any type of data analysis in Python, chances are you’ve probably used pandas. Though widely used in the data world, if you’ve run into space or computational issues with it, you’re not alone. This post discusses several faster alternatives to pandas.
R’s data table in Python
If you’ve used R, you’re probably familiar with the data.table package. A port of this library is also available in Python. In this example, we show how you can read in a CSV file faster than using standard pandas. For our purposes, we’ll be using an open source dataset from the UCI repository.
import datatable
start = time.time()
os_scan_data = datatable.fread("OS Scan_dataset.csv", header = None)
end = time.time()
print(end - start)
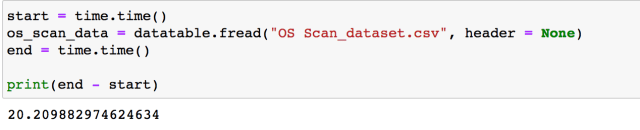
Using datatable, we can read in the CSV file in ~20 seconds. Reading the same file using pandas takes almost 76 seconds!

Next, we can also sort faster with datatable.
start = time.time() os_scan_data[0].sort() end = time.time() print(end - start)
In datatable, this takes ~0.002 seconds, but takes ~0.934 seconds in pandas.


In a later article, we’ll go into more detail with datatable. You can check out its documentation by clicking here.
The modin package
modin is another pandas alternative to speed up functions while keeping the syntax largely the same. modin works by utilizing the multiple cores available on a machine (like your laptop, for instance) to run pandas operations in parallel. Since most laptops have between four and eight cores, this means you can still have a performance boost even without using a more powerful server.
First, let’s install modin using pip. For this step, we’re going to install all the dependencies, which includes dask and ray. These will not be installed if you leave out the “[all]” piece of the installation command.
pip install modin[all]
Next, we can get started by importing the package like below. We’ll also import the time package to compare runtimes.
import modin.pandas as pd import time
For this example, we’ll be using the dataset found here.
os_scan_data = pd.read_csv("OS Scan_dataset.csv", header = None)
Also, we’re going to increase the size of the dataset artificially by simply duplicating the rows multiple times:
combined_data = pd.concat([os_scan_data, os_scan_data, os_scan_data])
This gives us a dataset with over 5 millions rows and and 115 columns.
Next, let’s create a new column using the map function. Using modin, we’ll able to generate the new field in around 0.03 seconds.
start = time.time() combined_data["test"] = combined_data[9].map(lambda val: "above" if val > 3 else "below") end = time.time() print(end - start)

If we were to use normal pandas, we get the following result at ~1.34 seconds.

Check out more about modin by clicking here.
The PandaPy library
PandaPy is another alternative to pandas. According to its documentation page, PandaPy is recommended as a potential faster alternative to pandas when the data you’re dealing with has less than 50,000 rows, but possibly as high as 500,000 rows, depending on the data. Another benefit of this package is that it often reduces the amount of memory needed to store datasets when you have mixed data types.
PandaPy can be download via pip:
pip install pandapy
For this example, we’ll use a credit card dataset from Kaggle. Now, we can read in the data. In PandaPy, the dataset is read in as a structured array.
import pandapy as pp
# read in dataset
credit_data = pp.read("creditcard.csv")
# get descriptive stats
pp.describe(credit_data)

General column operations are similar – for example, we can divide two columns just like in pandas:
credit_data["V1"] / credit_data["V2"]
Similarly, we can get the mean of a column just like pandas:
credit_data["V1"].mean()
See documentation for PandaPy here.
numpy
Several pandas functions can be implemented more efficiently using numpy. For example, if you want to calculate quantiles, like the 90% or 95%, etc., you can use either pandas or numpy. However, numpy will generally be faster.
# pandas start = time.time() q = np.arange(0.05, 1, 0.05) quantiles = [email_data.W.quantile(val) for val in q] end = time.time() print(end - start) # numpy start = time.time() q = np.arange(0.05, 1, 0.05) quantiles = [np.quantile(email_data.W, val) for val in q] end = time.time() print(end - start)

Conclusion
That’s all for this post! These are just a few of the alternatives to pandas. If you’d like to see tutorials on other alternatives, feel free to let me know. Also, if you enjoyed reading this article, make sure to share it with others! Check out my other Python posts by clicking here.