
Background
RoboBrowser is a Python 3.x package for crawling through the web and submitting online forms. It works similarly to the older Python 2.x package, mechanize. This post is going to give a simple introduction using RoboBrowser to submit a form on Wunderground for scraping historical weather data.
Initial setup
RoboBrowser can be installed via pip:
pip install robobrowser
Let’s do the initial setup of the script by loading the RoboBrowser package. We’ll also load pandas, as we’ll be using that a little bit later.
from robobrowser import RoboBrowser import pandas as pd
Create RoboBrowser Object
Next, we create a RoboBrowser object. This object functions similarly to an actual web browser. It allows you to navigate to different websites, fill in forms, and get HTML from webpages. All of a RoboBrowser object’s actions are completely invisible, so you won’t actually see a physical browser while any of this is happening.
Using our object, browser, we navigate to Wunderground’s historical weather main site (see https://www.wunderground.com/history). This is done using the open method, as below.
'''Create RoboBrowser object
This will act similarly to a typical web browser'''
browser = RoboBrowser(history=True)
'''Navigate browser to Wunderground's historical weather page'''
browser.open('https://www.wunderground.com/history')
Filling out the form
Next, let’s get the list of forms on the webpage, https://www.wunderground.com/history.
forms = browser.get_forms()

Above, we can see there are two forms on the webpage. The last of these is the one we need, as this is what we’ll use to submit a zip code with a historical date to get weather information. You can tell this by looking at the inputs in the print-out above of forms i.e. code, month, day etc.
form = forms[1]
Inputting data into our form is similar to adding values to a dictionary in Python. We do it like this:
'''Enter inputs into form''' form['code'] = '12345' form['month'] = 'September' form['day'] = '18' form['year'] = '2017'
As you can see, our inputs require a zip code (just called ‘code’ in the html), along with values for month, day, and year.
Now, we can submit the web form in one line:
'''Submit form''' browser.submit_form(form)
You can get the HTML of the page following submission using the parsed method of browser.
With the pandas read_html method, we can get the HTML tables on the page. In our example, we pull just the 0th (Python indexed 0) table on the page.
'''Scrape html of page following form submission''' html = str(browser.parsed) '''Use pandas to get primary table on page''' data = pd.read_html(html)[0]
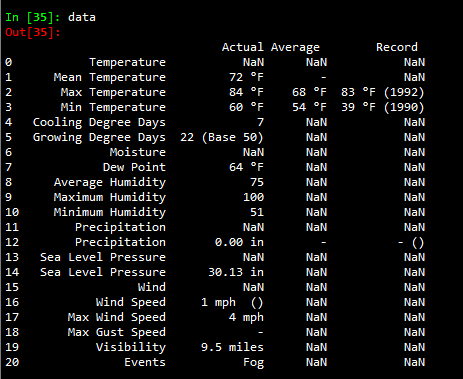
Putting it all together…
Let’s wrap what we’ve done into a function, like this:
def get_historical_data(code, month, day, year):
'''Create RoboBrowser object
This will act similar to a typical web browser'''
browser = RoboBrowser(history=True)
'''Navigate browser to Wunderground's historical weather page'''
browser.open('https://www.wunderground.com/history')
'''Find the form to input zip code and date'''
forms = browser.get_forms()
form = forms[1]
'''Enter inputs into form'''
form['code'] = code
form['month'] = month
form['day'] = day
form['year'] = year
'''Submit form'''
browser.submit_form(form)
'''Scrape html of page following form submission'''
html = str(browser.parsed)
'''Use pandas to get primary table on page'''
data = pd.read_html(html)[0]
return data
We now have a function we can call by passing a zip code with a particular month, day, and year.
get_historical_data('23456','September','18','2000')
get_historical_data('23456','March','18','2000')
We can simplify the parameters we’re passing so that we just need to input a zip code with a date, rather than three separate arguments for month, day, and year, respectively. We’ll do this by converting a date input from the user to a pandas timestamp, which allows us to parse out these needed attributes about the date.
def get_historical_data(code, date):
'''Create RoboBrowser object
This will act similar to a typical web browser'''
browser = RoboBrowser(history=True)
'''Navigate browser to Wunderground's historical weather page'''
browser.open('https://www.wunderground.com/history')
'''Find the form to input zip code and date'''
forms = browser.get_forms()
form = forms[1]
'''Convert date to pandas timestamp'''
date = pd.Timestamp(date)
'''Enter inputs into form'''
form['code'] = code
form['month'] = date.month
form['day'] = date.day
form['year'] = date.year
'''Submit form'''
browser.submit_form(form)
'''Scrape html of page following form submission'''
html = str(browser.parsed)
'''Use pandas to get primary table on page'''
data = pd.read_html(html)[0]
return data
So calling our function now looks like this:
get_historical_data("23456", "9/18/2000")
get_historical_data("23456", "3/18/2000")
See more Python articles on this site here. If you’re interested in learning more about web scraping with Python, check out Web Scraping with Python, or see other recommended coding books at this link.
