About Pyply
Pyply is a package designed to incorporate several R functions into Python (3.x). A few other functions are also included to help with data manipulation.
If you’re coming from R and miss having functions like sapply or lapply, this package is for you.
Installation
Pyply can be installed via pip (using all lowercase):
Requirements
Pyply requires the following packages to be installed:
collections functools pandas
The above packages are included in a standard installation of Anaconda.
Methods
Pyply comes with one module, also named pyply. This module contains the following methods:
flatten ifelse is_DataFrame is_dict is_float is_int is_list is_str is_tuple lapply mode rapply sapply split switch unsplit
Method: flatten(LIST)
Flattens a list of lists. Outputs the new list.
Possible Parameters
LIST Input list of sub-lists, or other elements. The output will flatten any sub-list within the input list.
Examples
sample_list = [[3,4,5],[6,7,8],[9,10,'c','d']]
{kind=link}
Method: ifelse(EXPR, flow1, flow2)
Single-line, functional version of if / else. Based off R’s ifelse function.
Possible Parameters
EXPR Expression to be evaluated as True / False flow1 If EXPR is True, then flow1 will be returned flow2 If EXPR is False, then flow2 will be returned
Examples
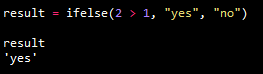
result = ifelse(2 > 1, "yes", "no")
result
{kind=link}
Methods: Boolean is_* functions
All of the below methods take a single parameter, x, and return a Boolean result. Each one tests whether the input is of a particular data type e.g. is_DataFrame returns True if the input, x, is a pandas data frame; is_str tests if an input is a string etc.
is_DataFrame is_dict is_float is_int is_list is_str is_tuple
Method: lapply(OBJECT, func, keys = None)
Based off R’s lapply function. Applies a function to every element of a list, tuple, or dictionary. Returns a dictionary. Lambda functions are supported in the func parameter.
Possible Parameters
OBJECT An object of type list, tuple, or dictionary func The function to be applied to each element in OBJECT keys The keys that the returned dictionary should have. The default is None, meaning that the returned result will have enumerated keys (e.g. inputting a list of five elements through lapply will result in a dictionary with keys 0, 1, 2, 3, and 4).
Examples
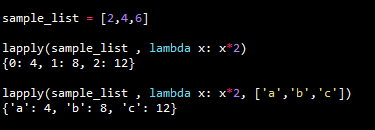
sample_list = [2 , 4 , 6]
lapply(sample_list , lambda x: x*2)
lapply(sample_list , lambda x: x*2, ['a','b','c'])
{kind=link}
Method: mode(OBJECT)
Finds the statistical mode of a list or tuple. If there is a tie, a list is returned with each element comprising the tie.
Possible Parameters
OBJECT A list or tuple
Examples
sample_list = [2 , 2, 4, 5, 6, 7, 2]
mode(sample_list)
second_sample = [2 , 2, 4, 5, 6, 7, 2, 7, 7]
mode(second_sample)
{kind=link}
Method: rapply(OBJECT, func, keys = None, _type = None)
Based off R’s rapply function. Applies a function to every element to a list, tuple, or dictionary, provided the element has type equal to the _type parameter.
If the input parameter, OBJECT, is a list or tuple, then a list is returned. If OBJECT is a dictionary, then a dictionary is returned.
Like lapply and sapply, lambda functions are supported in the func parameter.
Possible Parameters
OBJECT An object of type list, tuple, or dictionary func The function to be applied to each element in OBJECT keys The keys that the returned dictionary should have. The default is None, meaning that the returned result will have enumerated keys (e.g. inputting a list of five elements through rapply will result in a dictionary with keys 0, 1, 2, 3, and 4). _type The data type of the elements in OBJECT that func should be applied to (e.g. if _type = int, then func will only be applied to the integers in OBJECT).
Examples
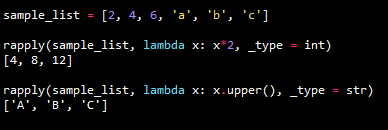
sample_list = [2, 4, 6, 'a', 'b', 'c']
rapply(sample_list, lambda x: x*2, _type = int)
rapply(sample_list, lambda x: x.upper(), _type = str)
{kind=link}
Method: sapply(OBJECT, func, return_type = list)
Based off R’s sapply function. Applies a function to every element in a list or tuple. Returns a list.
Like lapply and rapply, lambda functions are supported in the func parameter.
Possible Parameters
OBJECT A list or tuple func The function to be applied to each element in OBJECT return_type Data type of the object that should be returned. Default is list, but can also be tuple.
Examples
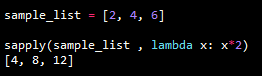
sample_list = [2, 4, 6]
sapply(sample_list , lambda x: x*2)
{kind=link}
Method: split(df, field)
Based off R’s split function. Splits a data frame by the different values of a field. Returns an OrderedDict (from the collections package). The keys of the OrderedDict are the distinct values in the field paramter. Each corresponding OrderedDict value is
Possible Parameters
df A data frame field A string -- the name of the field that df should be split on
Examples
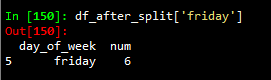
from pyply.pyply import split
df = pd.DataFrame()
df['day_of_week'] =['sunday','monday','tuesday','wednesday','thursday','friday','saturday']
df['num'] = [1,2,3,4,5,6,7]
df_after_split = split(df , "day_of_week")
df_after_split['friday']
{kind=link}
Method: switch(EXPR , *args,**kwargs)
Based off the switch function from R and other languages. Returns a selection from a list of choices.
Possible Parameters
EXPR This can be an int or a string *args A list or tuple **kwargs Additional keyword parameters as needed. See examples below
Examples
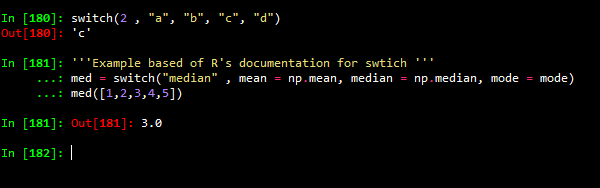
import numpy as np
'''simple example '''
switch(2 , "a", "b", "c", "d")
'''Example based of R's documentation for swtich '''
med = switch("median" , mean = np.mean, median = np.median, mode = mode)
med([1,2,3,4,5])
{kind=link}
Method: unsplit(df_dict)
Based off R’s unsplit function; tries to reverse the split function by taking a dict (or OrderedDict) of data frames, and returning the result of stacking them together.
Possible Parameters
df_dict A dictionary or OrderedDict with data frames as values
Examples
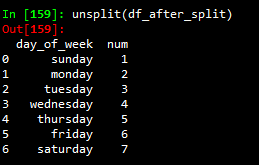
from pyply.pyply import unsplit
unsplit(df_after_split)
{kind=link}
To learn more about Python, see some book suggestions here.